Accelerate Your AI Deployments: Introducing NVIDIA Triton Integration with Matrice.ai
Jan 31, 2025
At Matrice.ai, we’re revolutionizing how businesses deploy and scale their AI models. Today, we’re thrilled to announce our integration with NVIDIA Triton Inference Server, a game-changing addition to our deployment capabilities.
This integration marks a pivotal moment in AI model deployment, offering unparalleled flexibility and performance across cloud, edge, and on-premise environments. Let’s explore how NVIDIA Triton transforms our platform and empowers organizations to achieve their AI goals more efficiently than ever.
What is NVIDIA Triton?
NVIDIA Triton is a powerful, open-source inference serving system that excels at deploying AI models at scale. It seamlessly supports major frameworks like TensorFlow, PyTorch, and ONNX, while being specifically optimized for NVIDIA GPUs to deliver exceptional performance and ensuring fast and efficient model inference with minimal latency and maximum throughput.
Matrice.ai’s Enhanced Deployment Architecture
Our integration with Triton creates a robust, enterprise-grade deployment platform:
1. Intelligent Deployment Orchestration
Automated environment detection and optimization
Smart load balancing across available resources
Dynamic scaling based on demand patterns
High-availability configuration options
2. Advanced MLOps Integration
Deployment scheduling management
Auto-scaling based on demand patterns
Comprehensive deployment logging
3. Performance Optimization Suite
Automatic model optimization with TensorRT
Resource usage optimization
Latency minimization
Throughput maximization
4. Enterprise-Grade Monitoring
Real-time performance dashboards
Detailed resource utilization metrics
Latency and throughput tracking
Predictive maintenance alerts
Custom monitoring endpoints
5. Cost-Efficient Resource Management
Intelligent resource allocation
Automatic scaling optimization
Cost-aware deployment strategies
Resource usage analytics
Key Benefits of NVIDIA Triton on Matrice.ai
Our Triton integration brings transformative advantages to your AI deployments:
1. Multi-Framework Support Compatibility
Deploy any model, regardless of its framework. Whether built in TensorFlow, PyTorch, ONNX, or other formats, Triton ensures smooth deployment and consistent performance. This flexibility empowers businesses to choose the best tools for their specific needs without deployment constraints.
2. Seamless Multi-Environment Deployment
Experience unmatched deployment flexibility across:
Cloud platforms (AWS, Google Cloud, Azure)
Edge devices (IoT, robotics, autonomous systems)
On-premise infrastructure
With intelligent auto-scaling capabilities, your AI workloads dynamically adjust to demand without manual intervention.
3. Sophisticated Model Management
Take control of your model lifecycle with:
Concurrent deployment of multiple model versions
Zero-downtime updates and rollbacks
Automated model versioning and tracking
Real-time performance monitoring
4. GPU-Optimized Performance
Leverage the full power of NVIDIA GPUs with:
Native support for A100, V100, and latest GPU architectures
TensorRT optimization for maximum throughput
Advanced memory management for optimal resource utilization
Ultra-low latency inference processing
5. High Concurrency Support
With Triton, you can handle high concurrency levels, allowing you to process multiple requests simultaneously. This is crucial for real-time applications where quick responses are essential.
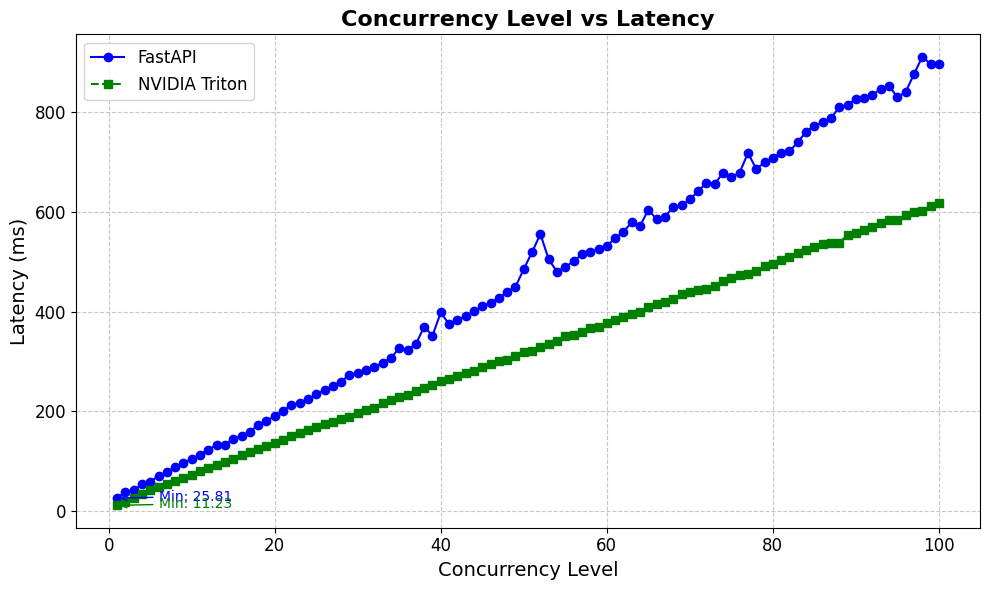
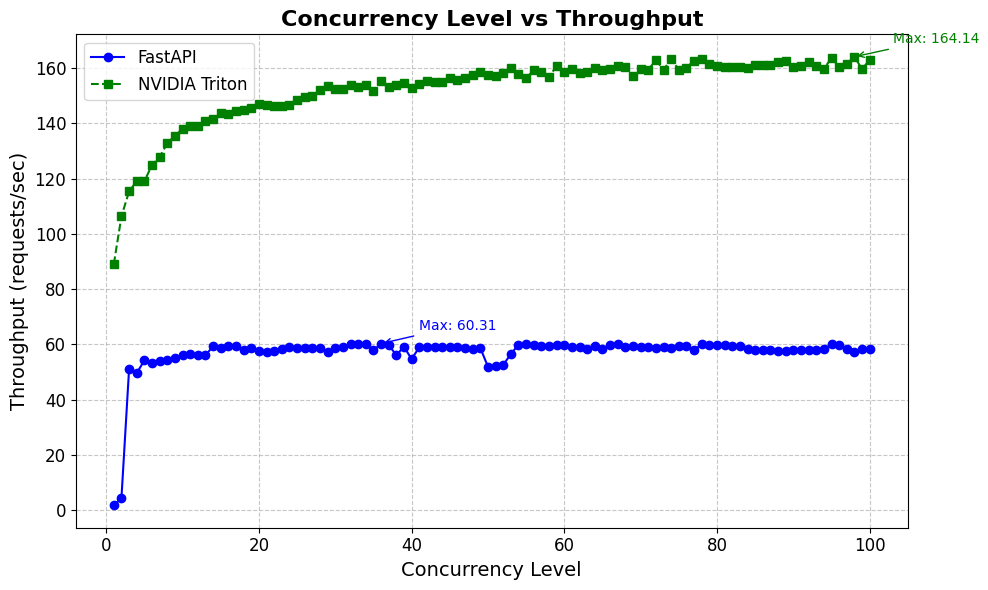
Real-World Impact
Organizations using Matrice.ai with Triton are seeing remarkable improvements:
Accelerated Deployment: Rapid model deployment across frameworks with minimal configuration
Enterprise-Grade Scalability: Flexible scaling from edge to cloud
Optimized Performance: Reduced latency and increased throughput through GPU optimization
Streamlined Operations: Automated deployment and versioning capabilities
Cost Optimization: Efficient resource utilization and improved price-performance ratio
Looking Ahead
The integration of NVIDIA Triton with Matrice.ai represents more than just a technical advancement - it’s a transformation in how organizations deploy and manage AI at scale. We’re enabling businesses to focus on innovation while we handle the complexities of deployment and optimization.
Our commitment to pushing the boundaries of AI deployment continues. We’re already working on exciting new features including:
Advanced automated optimization techniques
Enhanced edge deployment capabilities
Expanded framework support
Advanced monitoring and analytics tools
Join us in revolutionizing AI deployment. Experience the power of Matrice.ai with NVIDIA Triton today.