RT-DETR: The Transformer Revolutionizing Real-Time Object Detection
Matrice proudly presents RT-DETR, a revolutionary leap in real-time object detection. Combining cutting-edge transformer technology with unparalleled speed and accuracy, RT-DETR takes its place as the definitive model for detection tasks in today’s AI landscape. Now available on the Matrice platform, it’s never been easier to integrate state-of-the-art object detection into your projects. Train, deploy, and evaluate effortlessly—start your journey with RT-DETR today!
The Matrice platform is your gateway to the future of AI. With an intuitive interface and access to NVIDIA’s latest GPUs, the platform simplifies every step of the process, from dataset preparation to deployment. Designed for researchers, developers, and businesses alike, Matrice handles the technical complexities so you can focus on innovation.
Just upload your dataset, configure your preferred settings, and let RT-DETR showcase its unmatched power. Whether you’re working on autonomous vehicles, surveillance, or robotics, Matrice ensures you achieve top-tier results with minimal effort. Our seamless pipeline and robust infrastructure provide a hassle-free experience, empowering you to create, optimize, and deploy with confidence.
In a world where object detection defines progress across industries, RT-DETR sets a new benchmark for real-time performance. It’s more than a model; it’s the catalyst for your next big breakthrough.
In the electrifying world of computer vision, a silent revolution is underway. Traditional object detection models like YOLO have long been the rock stars of the stage—blazing fast, but not without their quirks. Enter RT-DETR (Real-Time Detection Transformer), the new prodigy in town, setting a gold standard by blending precision, speed, and innovation.
But what makes RT-DETR so special?
A Bold New Era in Object Detection
Imagine spotting a ball mid-flight or detecting a pedestrian as a car zips down the street—all in the blink of an eye. RT-DETR was built for this.
Unlike older models that lean on post-processing tweaks like Non-Maximum Suppression (NMS) to clean up redundant detections, RT-DETR says, “Why bother?” It ditches NMS entirely, operating as an end-to-end powerhouse. Its innovative hybrid encoder brilliantly handles multi-scale features, ensuring that no object—big or small—goes unnoticed.
And Guess what, DETRs beat YOLOs on Real-time Object Detection!
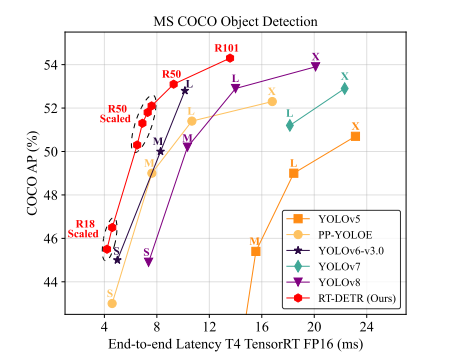
Why Speed and Accuracy Matter
Here’s the kicker: RT-DETR doesn’t just aim to be fast; it dominates the leaderboard.
Performance Snapshot:
Accuracy: A jaw-dropping 53.0% Average Precision (AP) on the COCO val2017 dataset.
Speed: Lightning-fast at 114 FPS on a modest T4 GPU.
This isn’t just evolution—it’s a quantum leap forward, rivaling the latest YOLO variants and then some.
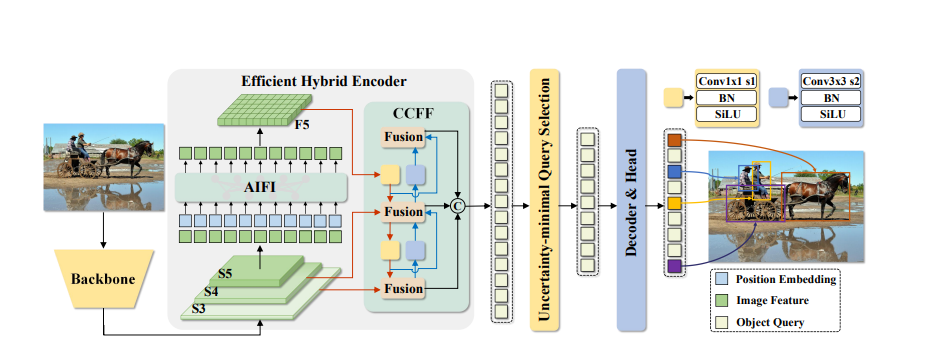
How Does It Work? Architecture Breakdown
At the core of RT-DETR is a cutting-edge transformer-based architecture, which differentiates it from previous object detection models. Let’s break down the key aspects that make it unique:
1. Hybrid Encoder-Decoder Design
RT-DETR’s architecture integrates a hybrid encoder-decoder design—something traditional CNN-based models lack. The encoder extracts high-quality feature maps from the input image, while the decoder is responsible for interpreting these features into object queries. These queries represent potential objects in the scene, and the decoder’s job is to refine these queries for detection. This dual approach allows RT-DETR to learn global dependencies across the image, enabling better detection of objects, even in complex scenes.
2. IoU-Aware Query Selection
One of RT-DETR’s standout features is its IoU-aware query selection. By incorporating information about the Intersection over Union (IoU) between predicted bounding boxes and ground truth objects, RT-DETR enhances the initial positioning of queries. This process reduces the chances of false positives and improves the model’s precision—something especially important when working with small or densely packed objects.
3. Multi-Scale Feature Fusion
RT-DETR excels at handling objects across a variety of scales. Its hybrid encoder can fuse multi-scale features, which helps the model capture both fine details (small objects) and broader contexts (large objects) without missing anything. This feature ensures that RT-DETR can detect everything from tiny pedestrians to towering vehicles with the same level of accuracy.
4. End-to-End Processing
RT-DETR removes the need for complex post-processing steps, such as Non-Maximum Suppression (NMS), that are typically used in traditional object detection models to clean up redundant predictions. By designing the system to work end-to-end, the model minimizes latency and eliminates potential sources of error in post-processing. This results in faster and more efficient real-time object detection.
Real-World Power: From Smart Cities to AI Labs
Here’s where RT-DETR shines brightest:
Autonomous Vehicles: Split-second decisions on obstacles, pedestrians, and traffic signs.
Surveillance: Tracking objects of interest with pinpoint accuracy, even in crowded environments.
Robotics: Giving robots eagle eyes for seamless interaction in dynamic spaces.
With RT-DETR, AI doesn’t just keep up—it takes the lead.
Why Should You Care?
Because this isn’t just another model—it’s a glimpse into the future. A future where AI systems think faster, react smarter, and adapt like never before.
If you’re an innovator, engineer, or just someone with a thirst for groundbreaking tech, RT-DETR deserves a spot on your radar. It’s not just a tool; it’s a game-changer.
So, what’s next? Dive in and explore how RT-DETR is transforming the landscape of computer vision. The revolution is here, and it’s real-time.
Curious to learn more? Want to experiment? Go to the Matrice platform now and start training the RT-DETR models! Learn more about training and other actions at Tutorials

Ashray Gupta
ML Engineer, Matrice.ai
Think CV, Think Matrice
Experience 40% faster deployment and slash development costs by 80%